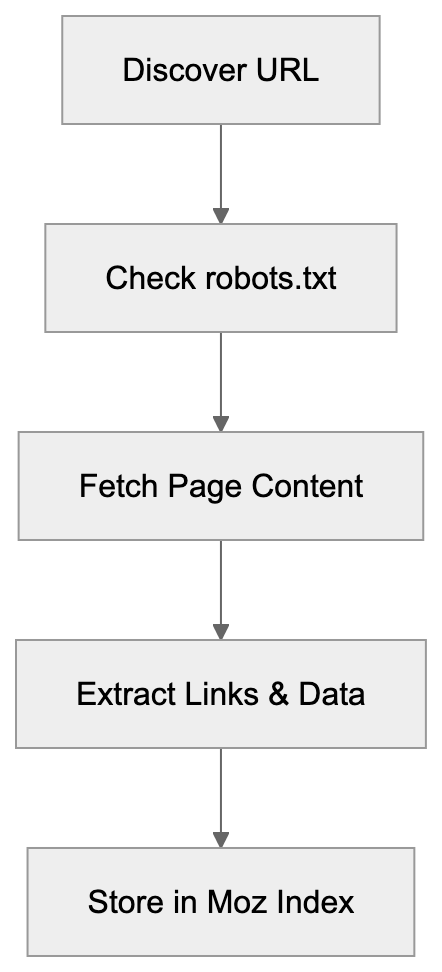
Understanding DotBot: Moz's SEO Crawler for Domain Authority
Explore DotBot, Moz's powerful SEO crawler used in domain authority calculations and link data collection.
14 min read
Explore DotBot, Moz's powerful SEO crawler used in domain authority calculations and link data collection.
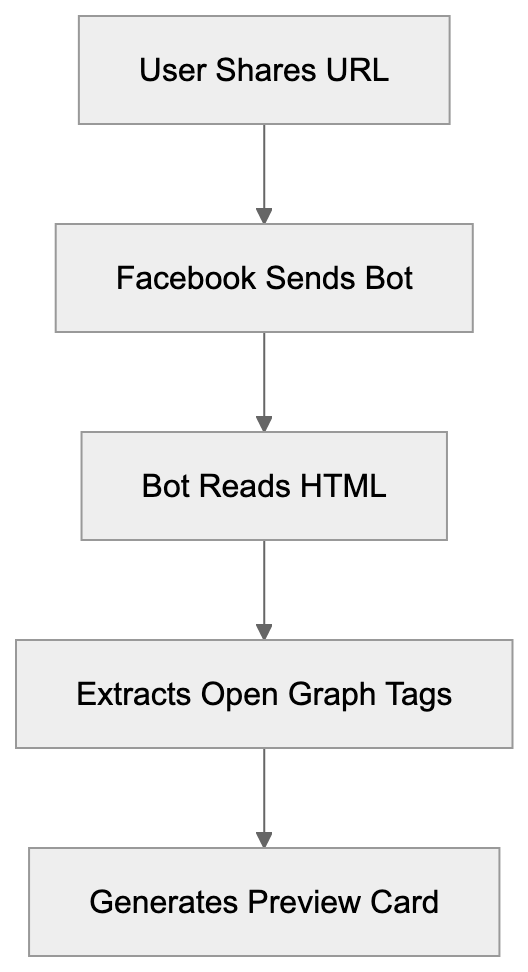
Learn what facebookexternalhit is, how it works for Facebook link previews, and best practices for handling this Meta crawler on your website.
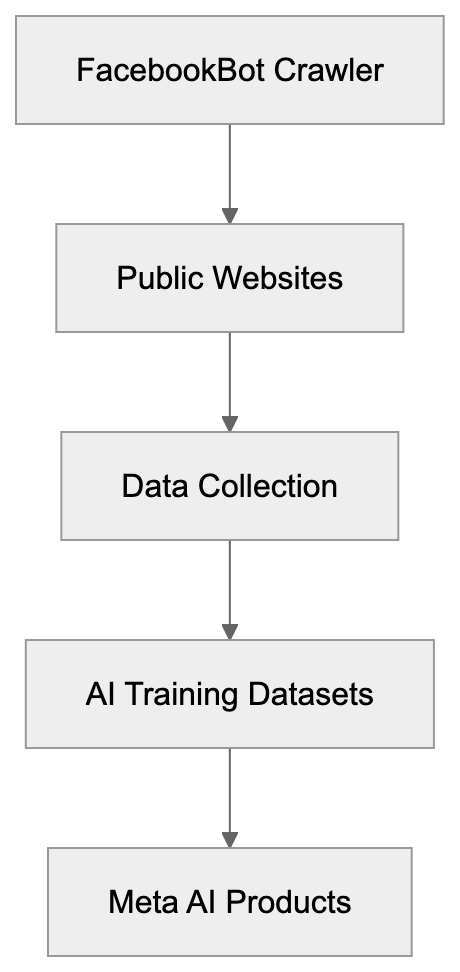
Learn about FacebookBot's role in AI training for Meta's models, user-agent details, documentation, and how to block it from your website.
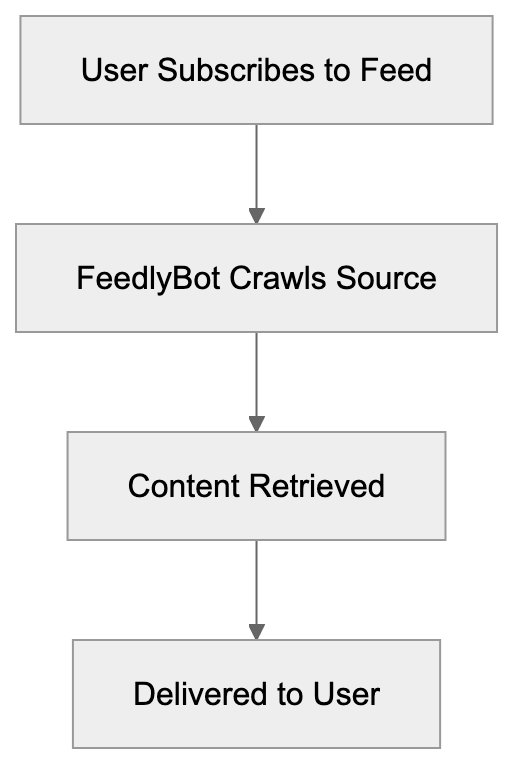
Learn about FeedlyBot, its role in feed retrieval, legitimate RSS use, and blocking implications for Feedly users.
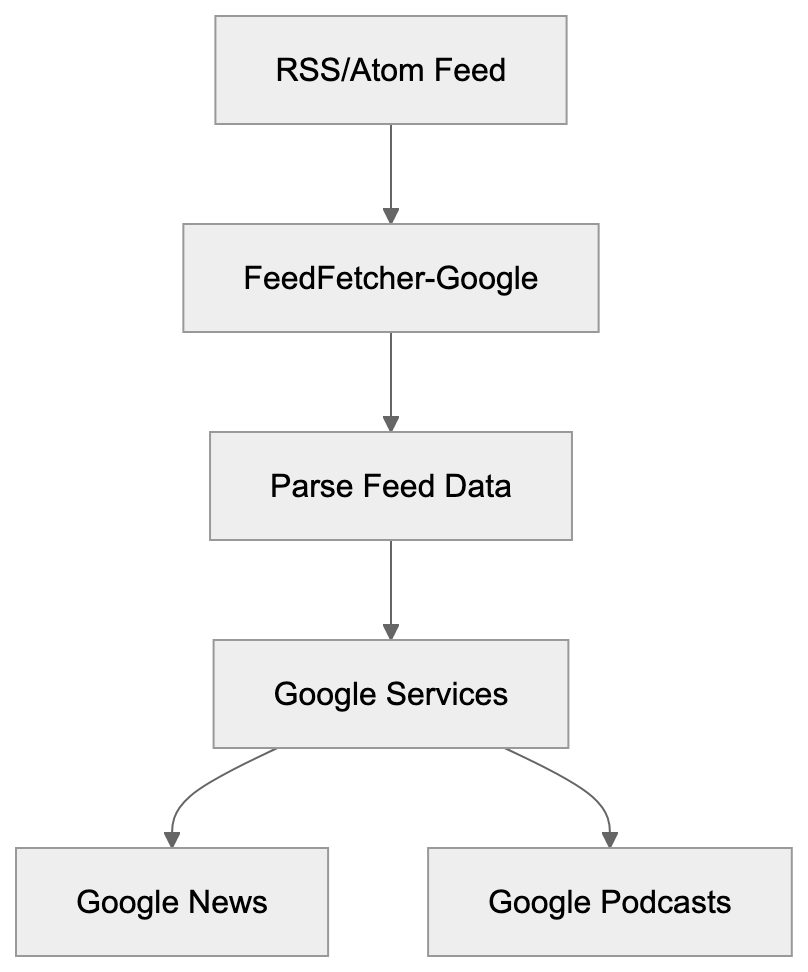
Learn about FeedFetcher-Google bot, how it crawls RSS feeds for Google services, user-agent details, and blocking considerations for publishers.
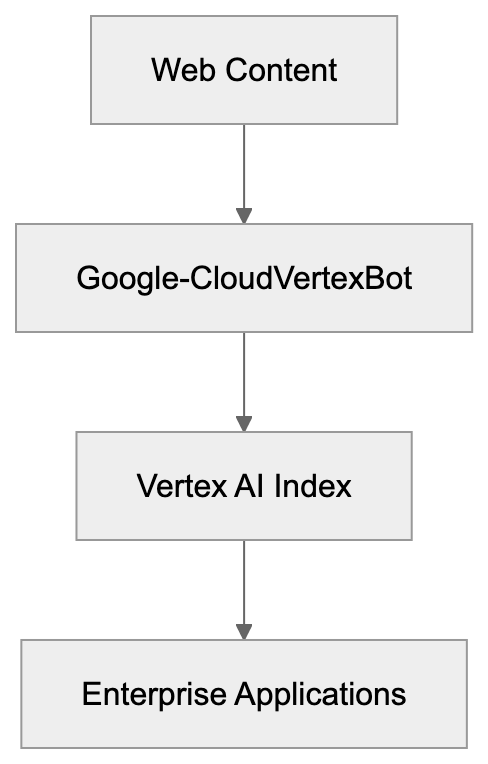
Learn about Google-CloudVertexBot features, purposes, blocking methods, and Vertex AI Search integration for developers and businesses.
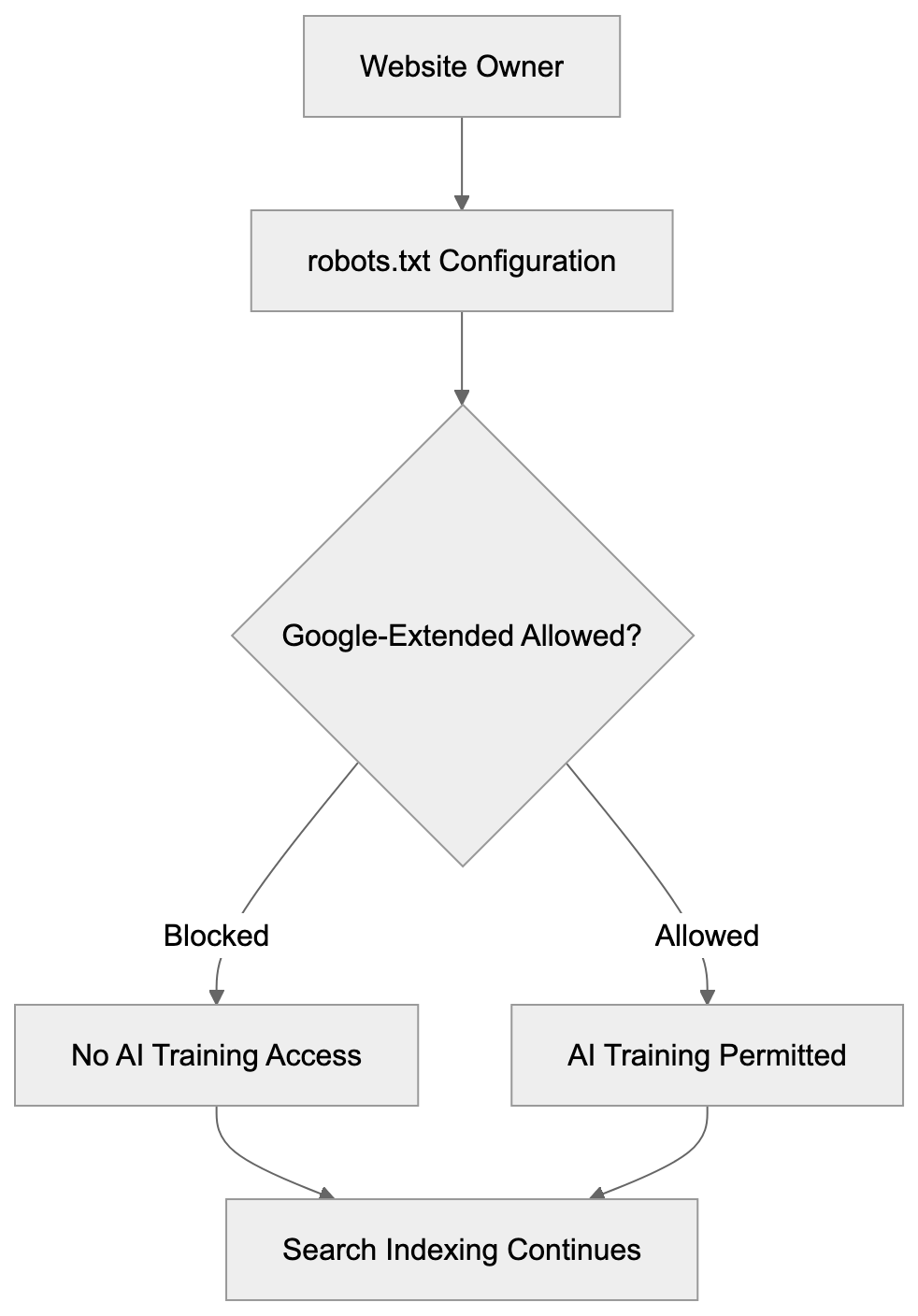
Learn how Google-Extended controls AI training access via robots.txt without affecting search rankings. Block Gemini and Vertex AI crawlers properly.
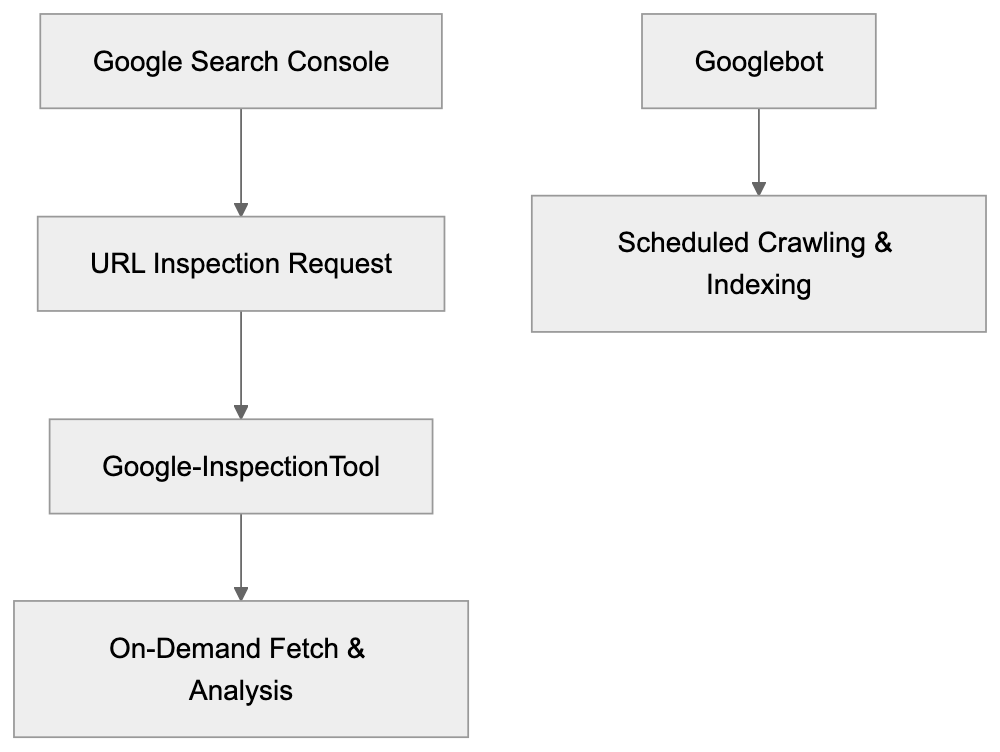
Learn how Google-InspectionTool powers Search Console's URL inspection for on-demand crawling, SEO testing, and debugging website issues.
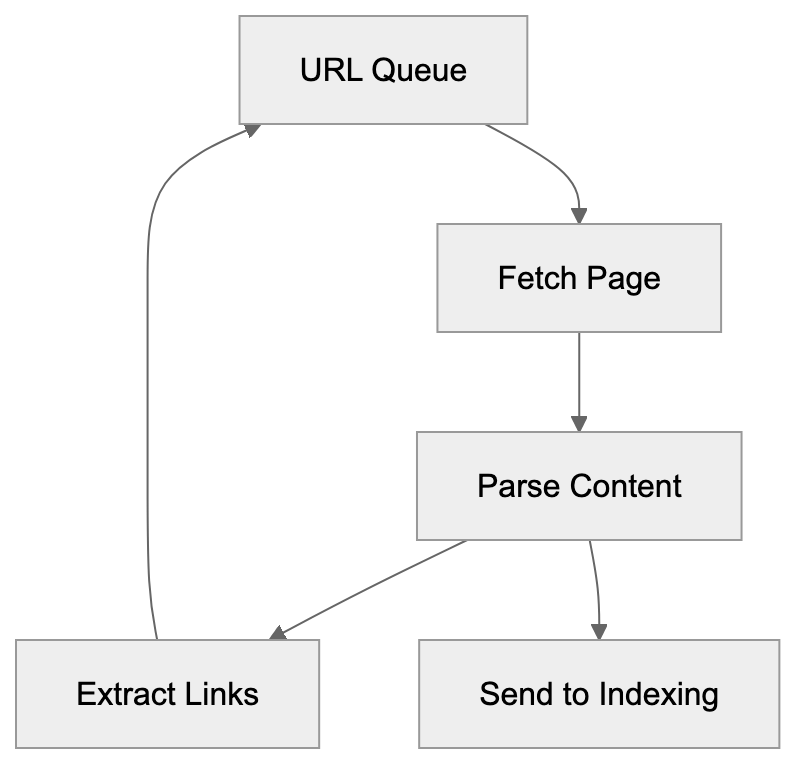
Learn how Googlebot works, its user-agent types, crawl budget management, and relationship to Google-Extended for AI training data collection.